반응형
뇌는 어떻게 보상을 예측하는가?
Schultz et al. (1997)의 도파민과 예측 보상 시스템 연구
1. 우리는 어떻게 보상을 기대할까?
심리학과 신경과학에서는
오랫동안 다음과 같은 질문에 관심을 가져왔습니다.
- 사람은 왜 특정 행동을 반복하고, 어떤 때에는 포기할까?
- 보상이 주어질지 모르는 상황에서도 왜 기대하게 될까?

Schultz, Dayan, & Montague(1997)는
도파민 뉴런이 보상을 예측하고 학습하는 핵심 역할을 한다는
획기적인 실험을 통해,
행동 경제학과 마케팅 전략의 과학적 기초를 제공했습니다.

Schultz, W., Dayan, P., & Montague, P. R. (1997). A neural substrate of prediction and reward. Science, 275(5306), 1593-1599.
반응형
2. 연구 목적: 도파민의 역할은 '쾌감'이 아닌 '예측 오차'?
기존에는 도파민을 단순히 “기쁨의 신경전달물질”로 이해하는 경향이 많았습니다.
그러나 이 연구는 다음과 같은 새로운 가설을 세웁니다:
- 도파민은 단순한 보상 자체가 아니라 “보상 예측 오차(prediction error)”를 인코딩한다.
- 즉, 예상보다 좋은 일이 생기면 도파민 분비가 증가하고, 예상보다 나쁘거나 없으면 감소한다는 것입니다.
이 가설을 검증하기 위해 연구진은 원숭이를 대상으로 신경생리학적 실험을 설계했습니다.
3. 연구 방법: 원숭이의 도파민 뉴런 반응 측정
【대상】 : 살아 있는 원숭이
【측정】 : 보상(과일즙)이 주어졌을 때 도파민 뉴런의 반응을 미세전극으로 실시간 측정
【조건】
- 아무 예고 없이 보상이 주어질 때
- 특정 신호(조건자극) 후 보상이 예측될 때
- 신호가 있었지만 보상이 제공되지 않을 때
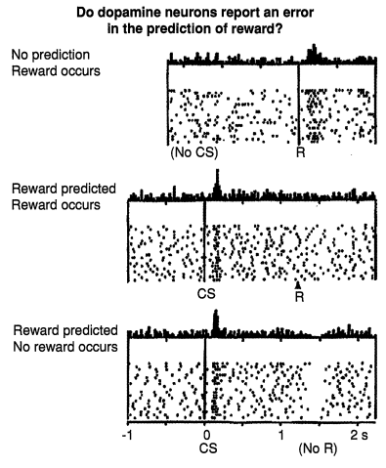
4. 연구 결과: 핵심은 "예상과 실제의 차이"
- 예고 없이 보상 제공 시: 도파민 뉴런 강한 반응
- 보상이 예측 가능해질수록: 반응은 보상 자체가 아니라 예측 신호에 옮겨감
- 예상된 보상이 제공되지 않을 경우: 도파민 반응이 감소하거나 멈춤
→ 이 결과는 도파민이 보상 자체보다 ‘보상의 예측 오차’를 신경 신호로 전환한다는 사실을 명확히 보여줍니다.
즉, 도파민은 "생각보다 잘 됐다!"는 경험에 가장 강하게 반응한다는 것입니다.
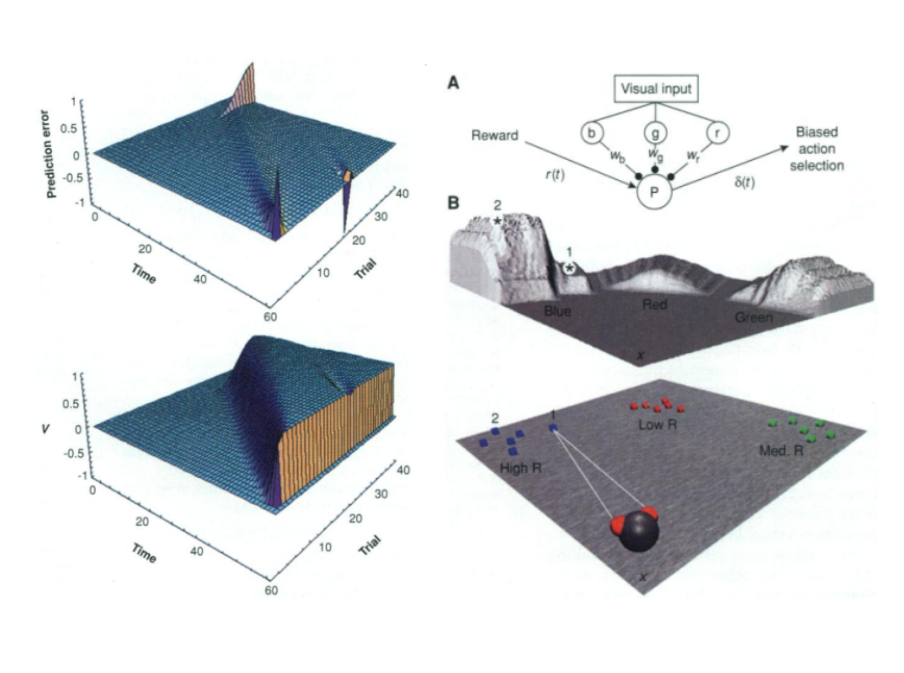
5. 시사점: 보상 시스템 = 학습 시스템
이 연구는 단순한 쾌감 이론을 넘어서 다음과 같은 시사점을 제공합니다.
- 보상 기반 학습(reinforcement learning)의 신경학적 기초 제공
- 도파민 시스템은 기대와 실제 결과의 차이를 통해 행동을 조절하고 학습을 유도
- 심리학, 행동경제학, 머신러닝, 마케팅 등 여러 분야의 ‘예측 중심 모델’의 토대 제공
6. 마케팅·정책 적용 사례
[1] 가챠, 랜덤박스 전략
- 소비자가 받을 보상의 확률과 크기를 정확히 예측할 수 없게 설계
- 예측 오차를 유발해 도파민 분비 극대화, 행동 반복 유도
- 대표 사례: 모바일 게임의 뽑기 시스템, 일부 온라인 쇼핑몰의 랜덤박스
[2] 리워드 시스템
- 일정 행동 후 불확실한 시점에 보상을 제공하여 ‘기대 → 만족 → 반복 행동’ 구조 생성
- 예: 스탬프 카드, 출석체크 이벤트
[3] 사회적 피드백 설계
- SNS ‘좋아요’, 푸시 알림은 예측 불가능하게 등장해 강한 예측 오차 자극
- 사용자로 하여금 계속해서 앱을 확인하도록 유도
Schultz et al.(1997)은
‘보상이 아니라, 예측된 보상과 실제 보상의 차이’가
도파민 시스템을 자극한다는 사실을 밝힘으로써,
인간 행동의 동기를 보다 정밀하게 설명할 수 있게 했습니다.
이 연구는 현재 강화학습 모델의 생물학적 근거가 되었으며,
마케팅, UX 디자인, 게임 설계, 교육 정책 등에 실질적인 영향을 미쳤습니다.
뇌는 예측하고, 행동은 도파민으로 강화된다!
반응형
'흥미로운 연구(논문) > 자연_의학' 카테고리의 다른 글
| 2024년, 지구온난화 1.5도 한계선 돌파! 기후위기 ‘레드라인’을 넘었다! (0) | 2025.11.04 |
|---|---|
| 미세먼지가 우울증을 부른다고?_연구결과 (0) | 2025.09.22 |
| 엄마의 사랑, 아이의 유전자를 바꾼다(후성유전학)._연구결과 (1) | 2025.09.22 |
| 먹는 것이 기분을 결정한다고?: 음식과 감정의 과학_연구결과 (0) | 2025.09.22 |
| 명상이 뇌를 어떻게 변화 시킬까?_[연구결과] (0) | 2025.09.22 |



